Inside Automated Sentiment Analysis
Posted 2010-03-25.This post details Biz360's automated sentiment analysis system, including our goals, how the system works, how we measure success, and the ways it can be used and misused. Before getting into the how or why, I want to start with the what. For our purposes, sentiment is the opinion of the author of an article towards the subject of an article. We classify sentiment into four possible categories.
Positive
- Arguing for something, saying something is a good product, talking about good things a person or company has done, enjoying something, liking something, preferring something. If a mostly positive post has a small portion that is negative, it is still positive.
Negative
- Arguing against something, saying something is a bad product, a bad experiences, talking about bad things a person or company has done, disliking or having problems with something. If a mostly negative post has a small portion that is positive, it is still negative
Neutral
- If an post doesn't express any opinion, doesn't present anyone or anything in a favorable or unfavorable way, and wouldn't lead someone to form an opinion for or against, it is neutral.
Mixed
- If an post is both positive and negative, such as saying something was good in some ways but bad in others, or if the post talks about different subjects and is positive toward one subject but negative to another, then rate the post as mixed.
The first question is why do you need automated sentiment. The simple answer is that there's just too much content. As conversations that used to take place over coffee and on street corners move to Twitter and forums, they become trackable. If a magazine with 100,000 readers mentions you in an article, you'll read that article and discuss what it's saying about you. If 10,000 people tell ten of their friends what they think of Kevin Smith vs. Southwest Air, you can't hope to read more than a small sampling. It's this later use case that we cared about.
- What portion of my coverage is positive, negative, etc?
- I got a spike in coverage on Monday. Was that spike positive or negative?
- What kinds of things are people saying that's positive? Negative?
We knew from the start that accuracy on the individual article level was never going to be that good. That is, if you want to know what the sentiment for some particular article is, the best thing to do is click on it, read it, and form your own opinion. With the help of Bill MacCartney, an NLP researcher from Stanford, we quickly honed in on the following design parameters:
- A statistical classification system using two classifiers to detect positive and negative, and another classifier to combine these results. We would start with a simple Naive Bayes classifier and a Decision Tree classifier to get everything working, and experiment with more advanced classifiers like the Linear MaxEnt classifier once we had a baseline to measure improvements.
- The system would be trained using lots of data from Mechanical Turk. Each item would be rated multiple times so we could throw out the results from raters who didn't understand or were not taking enough care.
- Our training data would be real social media content, drawn from all the types of social media we process (blogs, micro-blogs, etc).
At a very high level view, text classification systems get lumped into groups based on whether they are based on statistical learning from data, or whether they are based on hand-coded rules. Our system is solidly in the statistical camp. We were skeptical that a rule-based system could encompass the wide variety of topics and writing styles and the frequency of ungrammatical or misspelled content on the less formal parts of the Internet.
Our sentiment engine turns each post into a set of features, like ("good", "deal") -> 2, meaning the word "good" followed by the word "deal" occurs twice. This gets fed into a two-stage system. First, everything gets flagged for how positive it is (regardless of also being negative) and for how negative it is (regardless of how positive it is). Next, these get combined into the four categories that are displayed. So high positive sentiment and low negative sentiment would be positive, and high positive and high negative would be negative.
We really wanted a mixed category, because in terms of whether it's a post worth reading, someone who is saying both good and bad things about you is even more interesting than positive or negative. Consider the following three clips:
- I love my Kinesis Maxim keyboard, it's the best. My wrists feel great since I've been typing on it.
- Kinesis is stupid, the Maxim has a stupid layout. I had one for a while but I threw it out.
- I like my Kinesis Maxim, but the left alt key is too small and too far to the left.
Sure, the first one is what you hope everyone is saying, but reading these doesn't provide much value. The second one at least is an opportunity for damage control, but the third one is the real gold. In a system based on just a range from negative through neutral to positive, the positive and negative would cancel out and this kind of thing would get lumped into the neutral bucket.
This kind of statistical system isn't any good without good data, so we used an approach that gives us lots of good data quickly and cheaply. We sent out thousands of clips to Mechanical Turk, Amazon's "artificial artificial intelligence" where they were scored by ten humans each. The instructions they were given were exactly the definitions I gave above. Those aren't just descriptions of what we think the system produces, those are the starting point. When the results came back, the humans didn't always agree, and some agreed more than others. We threw out the ones who looked like they just didn't understand the problem at all or were clicking randomly since payment was per item. Of the remaining items, we still got disagreements, so we took the majority, so that if five people said positive, three said neutral and two said mixed, we'd used that clip as training data for positive. All of our data was real social media data. We evaluated one off-the-shelf solution which was trained on newspaper data, and when it said that "Comcast sucks!" was neutral, we gave up on that idea.
To evaluate our accuracy, we looked at a whole slew of numbers. We used a technique called k-fold cross validation, which means that we'd hold back some of our human-annotated data to use to evaluate how accurate the system is. A big challenge was that most of the content we got was neutral or positive, not mixed or negative. This makes it hard to use simple accuracy as the only metric. That is, if I have 90 items that should be classified as A and 10 items that should be classified at B, I could be 90% accurate by just saying everything was A. So I looked at the accuracy rates for each of the categories separately, and tried to balance them. Given my example with 90 A and 10 B, if I could get 90% accuracy, I'd really prefer 81 out of 90 As classified correctly and 9 out of the 10 Bs.
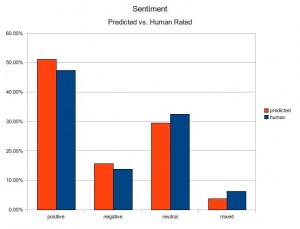
Of course, there's no "make mistakes evenly" button to press, but I think we found a combination that gives useful results. You can see in the attached chart of predicted vs. human-annotated sentiment that the errors are evenly spread across the categories. This illustrates what we mean when we say that sentiment, though it is only correct for about 2/3 of the individual items, is directionally accurate. If the system finds 100 articles for for a topic, and says 50 of them are positive, a lot of those will be wrong. Maybe you go through them and you see that 10 of them were neutral, four negative and one mixed. But when you go to the other categories, you'll find that the errors mostly balance out. Some of the neutral should have been positive, and so on. So maybe there should have been 52 positive.
There's a strong temptation when building an automated sentiment system to treat neutral as "I'm not sure". Computers make different kinds of mistakes than humans, and when the computer screws up something a human would have no trouble classifying correctly, it erodes confidence. The problem with this approach is that it focuses too much on not being wrong, and not enough on being right. If uncertain posts are rated as neutral, it changes the whole distribution of content. If you look at a topic and 75% of the content is "neutral", how much is really neutral and how much is swept under the rug because it didn't cross a confidence threshold? We treat neutral as just another category. To classify something that should be positive, negative, or mixed as neutral is just as incorrect as vice-versa.
I hope this has given you some insight into how Biz360's sentiment engine works, and lets you make better sense of the numbers you are seeing, or, if you are still comparing solutions, gives you things to look for and questions to ask. I'll be following this up in the future with another article explaining "entity" or topic-based sentiment.
This article was original posted on Biz360's Blog